


In the world of Kubernetes, ensuring high availability of application during maintenance and upgrades can be a frustrating this has happened to me most times. As you scale and manage containerized applications, minimizing downtime and maintaining service continuity becomes a huge challenge especially when a simple human error can cause service disruption. This is where the concept of Pod Disruption Budgets (PDBs) comes into play, today we will dive deep into the fundamentals of Pod Disruption Budget explore how to implement them in your Kubernetes clusters.
WHAT IS KUBERNETES POD DISRUPTION?
A Pod Disruption Budget is a Kubernetes resource or policy that helps you define the number of pod that must remain available during a disruption, whether you’re dealing with voluntary disruptions like node maintenance or unvoluntary disruptions like node failures, PDBs provide a way to safeguard your application’s stability and availability. they can be applied to a specific workload, such as deployment or Statefulset or a group of workloads using a label selector.
there are two types of disruption?
voluntary Disruption
involuntary Disruption
Voluntary Disruption: voluntary disruption can happen when
the application owner deletes the deployment managing the pods
updating the deployment pods template which causes a restart.
Involuntary Disruptions: can happen when
there is a node failure
the cluster admin deletes the nodes accidentally
there is a kernel related problem
there isn’t enough resources left on a node.

HOW DO POD DISRUPTION BUDGETS WORK?
what PDB’s do is tells kubernetes of the desired state of the cluster which you have orchestrated and enforced. this means there must be a minimal number of pods replica that must remain at any given time. when a voluntary disruption occurs Kubernetes identifies the set of pods that are subject to PDB and restricts any further deletion or disruptions. then Kubernetes reschedules those pods using a strategy that doesn’t clash with the PDB.
Importance of Pod Disruption Budgets (PDBs)
1. Prevents Unnecessary Downtime: PDBs ensure application availability during disruptions by defining the maximum number of pods that can be taken down simultaneously, preventing complete service outages.
2. Ensures Graceful Upgrades and Maintenance: During routine maintenance or cluster upgrades, PDBs control disruptions, ensuring that a minimum number of pods are always running to handle user requests.
3. Enhances Cluster Reliability through Controlled Disruptions : By specifying the number of pod disruptions an application can tolerate, PDBs help maintain reliability and resilience, crucial in large, dynamic environments.
4. Improves Node Management: Node maintenance, such as patching and upgrades, can be managed effectively without impacting application availability, thanks to PDBs.
5. Integrates with Cluster Autoscaler : PDBs work seamlessly with the Cluster Autoscaler, automatically adjusting the number of nodes while respecting PDB constraints to ensure application stability during scaling operations.
There are three main fields in PDB:
.spec.selector denotes the set of pods to which the PDB applies.
.spec.minAvailable it also denotes the minimal number of pods that must be available after eviction.
.spec.maxUnavailable this denotes the number of pods that can be unavailable after eviction.
Lets create our application using this manifest
- create a simple Mario demo app for your clients
apiVersion: apps/v1
kind: Deployment
metadata:
name: games-deployment
spec:
replicas: 8 # You can adjust the number of replicas as needed
selector:
matchLabels:
app: games
template:
metadata:
labels:
app: games
spec:
containers:
- name: mario-container
image: sevenajay/mario:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: games-service
spec:
type: LoadBalancer
selector:
app: games
ports:
- protocol: TCP
port: 80
targetPort: 80
deploy the application in your Kubernetes cluster with 8 replicas
kubectl apply -f games-deployment.yaml
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
games-deployment-68bcccb748-4gdp4 1/1 Running 0 35m 192.168.126.120 ip-192-168-106-62.ec2.internal <none>
<none>
games-deployment-68bcccb748-4hkps 1/1 Running 0 35m 192.168.72.216 ip-192-168-67-92.ec2.internal <none>
<none>
games-deployment-68bcccb748-fm48d 1/1 Running 0 35m 192.168.96.48 ip-192-168-106-62.ec2.internal <none>
<none>
games-deployment-68bcccb748-hsp4f 1/1 Running 0 35m 192.168.94.157 ip-192-168-67-92.ec2.internal <none>
<none>
games-deployment-68bcccb748-k26q6 1/1 Running 0 35m 192.168.83.27 ip-192-168-67-92.ec2.internal <none>
<none>
games-deployment-68bcccb748-kksnw 1/1 Running 0 35m 192.168.67.154 ip-192-168-67-92.ec2.internal <none>
<none>
games-deployment-68bcccb748-lh95r 1/1 Running 0 35m 192.168.107.174 ip-192-168-106-62.ec2.internal <none>
<none>
games-deployment-68bcccb748-tckkn 1/1 Running 0 35m 192.168.108.223 ip-192-168-106-62.ec2.internal <none>
<none>s
we can get the number of nodes available
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ip-192-168-106-62.ec2.internal Ready <none> 149m v1.30.0-eks-036c24b 192.168.106.62 <none> Amazon Linux 2023.5.20240701 6.1.94-99.176.amzn2023.x86_64 containerd://1.7.11
ip-192-168-67-92.ec2.internal Ready <none> 149m v1.30.0-eks-036c24b 192.168.67.92 <none> Amazon Linux 2023.5.20240701 6.1.94-99.176.amzn2023.x86_64 containerd://1.7.11
now the application is accessible
USE-CASE:
now let’s create our manifest file for the PDB and set the minAvailable size to 4 which means that out of 8 replicas 4 must be running even if there is a voluntary or involuntary disruption of the pods, we can also use maxUnavailable as well.
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: games-pdb
spec:
minAvailable: 4
selector:
matchLabels:
app: games
you can apply the pod disruption budget
kubectl apply -f "pdb.yaml"

Testing the PDB
let's test the PDB and create a Disruption, by draining the node and we monitor the pdb in action:
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data
kubectl drain ip-192-168-106-62.ec2.internal --ignore-daemonsets --delete-emptydir-data
node/ip-192-168-106-62.ec2.internal cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/aws-node-qg5kc, kube-system/kube-proxy-v2n2m
evicting pod default/games-deployment-68bcccb748-tckkn
evicting pod default/games-deployment-68bcccb748-fm48d
evicting pod default/games-deployment-68bcccb748-4gdp4
evicting pod default/games-deployment-68bcccb748-lh95r
pod/games-deployment-68bcccb748-fm48d evicted
pod/games-deployment-68bcccb748-4gdp4 evicted
pod/games-deployment-68bcccb748-lh95r evicted
pod/games-deployment-68bcccb748-tckkn evicted
node/ip-192-168-106-62.ec2.internal drained
then we drain the second node
kubectl drain ip-192-168-67-92.ec2.internal --ignore-daemonsets --delete-emptydir-data
node/ip-192-168-67-92.ec2.internal cordoned
Warning: ignoring DaemonSet-managed Pods: kube-system/aws-node-xp987, kube-system/kube-proxy-nww45
evicting pod default/games-deployment-68bcccb748-hsp4f
evicting pod default/games-deployment-68bcccb748-4n4zl
evicting pod kube-system/coredns-586b798467-p5pg9
evicting pod default/games-deployment-68bcccb748-kd7fb
evicting pod default/games-deployment-68bcccb748-k26q6
evicting pod default/games-deployment-68bcccb748-r7s57
evicting pod kube-system/coredns-586b798467-mpgmq
evicting pod default/games-deployment-68bcccb748-kksnw
evicting pod default/games-deployment-68bcccb748-5v6bn
evicting pod default/games-deployment-68bcccb748-4hkps
Monitor the progress and observe that the eviction API will retry to evict the pods until they can be rescheduled on another node.
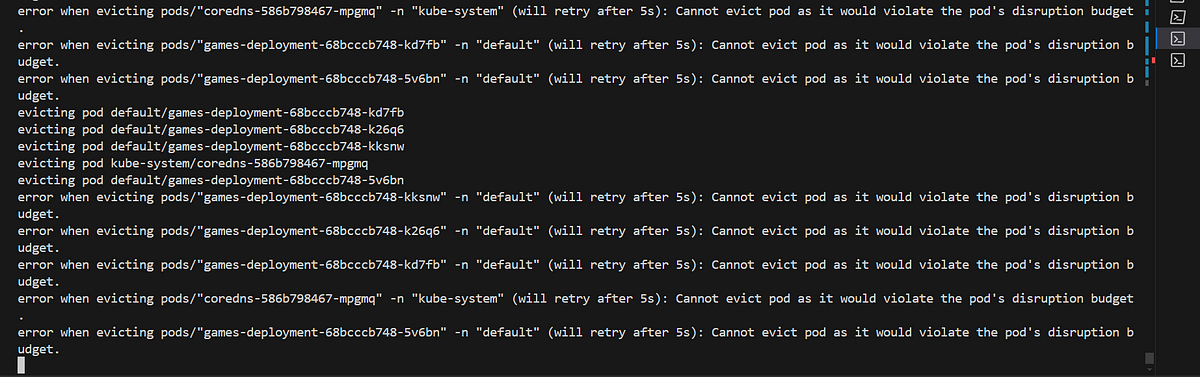
The nodes won’t be terminated due to the PDB contraints.
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE
KERNEL-VERSION CONTAINER-RUNTIME
ip-192-168-106-62.ec2.internal Ready,SchedulingDisabled <none> 6h20m v1.30.0-eks-036c24b 192.168.106.62 <none> Amazon Linux 2023.5.20240701 6.1.94-99.176.amzn2023.x86_64 containerd://1.7.11
ip-192-168-67-92.ec2.internal Ready,SchedulingDisabled <none> 6h20m v1.30.0-eks-036c24b 192.168.67.92 <none> Amazon Linux 2023.5.20240701 6.1.94-99.176.amzn2023.x86_64 containerd://1.7.11
then the pods ‘status’ is left on pending cause the nodes aren’t running as expected. we observed the minimum available pods in pdb are 4 pods
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
games-deployment-68bcccb748-2dvsq 0/1 Pending 0 60s <none> <none> <none> <none>
games-deployment-68bcccb748-5v6bn 1/1 Running 0 98s 192.168.84.6 ip-192-168-67-92.ec2.internal <none> <none>
games-deployment-68bcccb748-hjx6c 0/1 Pending 0 59s <none> <none> <none> <none>
games-deployment-68bcccb748-j9gfs 0/1 Pending 0 59s <none> <none> <none> <none>
games-deployment-68bcccb748-k26q6 1/1 Running 0 3h45m 192.168.83.27 ip-192-168-67-92.ec2.internal <none> <none>
games-deployment-68bcccb748-kd7fb 1/1 Running 0 99s 192.168.64.174 ip-192-168-67-92.ec2.internal <none> <none>
games-deployment-68bcccb748-kksnw 1/1 Running 0 3h45m 192.168.67.154 ip-192-168-67-92.ec2.internal <none> <none>
games-deployment-68bcccb748-s777t 0/1 Pending 0 60s <none> <none> <none> <none>
now we can uncordon the nodes to return the nodes back and make the pods schedulable.

IMPORTANT THINGS TO NOTE WHEN USING PDB’s
there are some factors to consider when creating pdb’s
mointoring the Pod Disruption Status
when using the Pdb policy in a single deployments it blocks the execution of the
kubectl draincommand so avoid using pdb in single deploymentusing
matchlabelsyou need to be clear to avoid overlapping selectors when deploying multipledon’t set
minAvailableto 100% you cant upgrade your cluster.if your set
maxUnavailableto 0% means you can not drain your node successfully.You can set the
.spec.unhealthyPodEvictionPolicyfield toAlwaysAllowand enable Kubernetes to evict unhealthy nodes when it drains a node.
Conclusion
Pod Disruption Budgets is a powerful resource in kubernetes which is critical for workloads to remain available during node maintenance or failures and minimizes the disruption of operations. there by ensuring that applications remain resilient and continue to serve users effectively.
see you all next time!