Using Lambda Function to read data from S3 Bucket on AWS
i am a dedicated and enthusiastic professional with a solid year of hands-on experience in crafting efficient and scalable solutions for complex projects in Cloud/devops. i have strong knowledge in DevOps practices and architectural designs, allowing me to seamlessly bridge the gap between development and operations team, I possess excellent writing abilities and can deliver high-quality solutions
In this post we will see how we automatically trigger a lambda function to read data from s3 bucket using cloud watch logs
Pre-requisites
- AWS account
STEP 1
create an Iam role
we will create an iam role and attach this permission
Login to your aws management console and on the navigate to IAM and on the sidebar click role on the iam console
then create a new role
under the use case, Choose Lambda
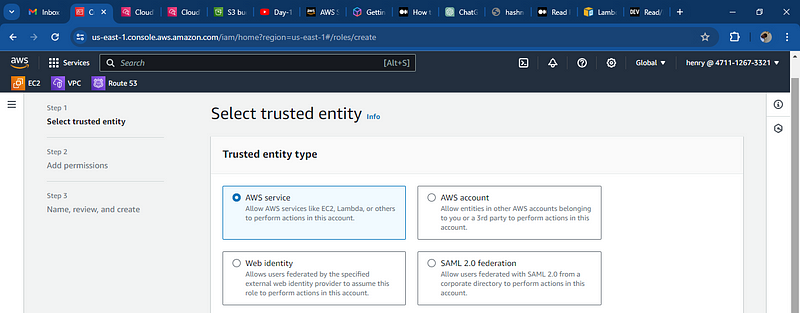
create role
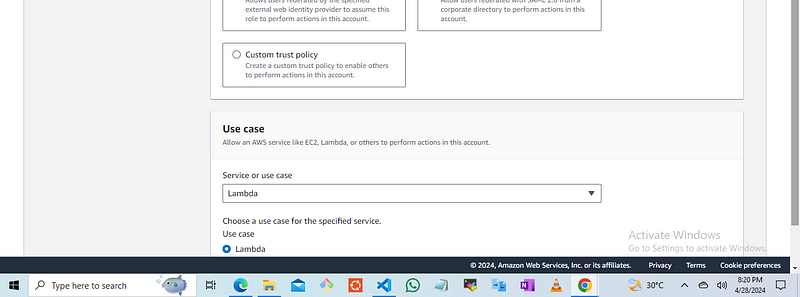
click on next then add permissions, Look for the permissions stated below and click on next
AmazonS3FullAccess
AWSLambdaBasicExecutionRole
AWSXRayDaemonWriteAccess
AmazonDMSCloudWatchLogsRole
CloudWatchEventsFullAccess
Enter the role Name i would use “s3-lambda-role”and then create role
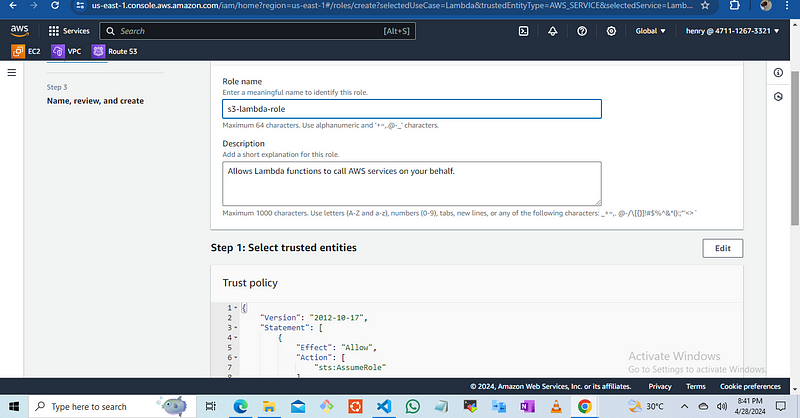
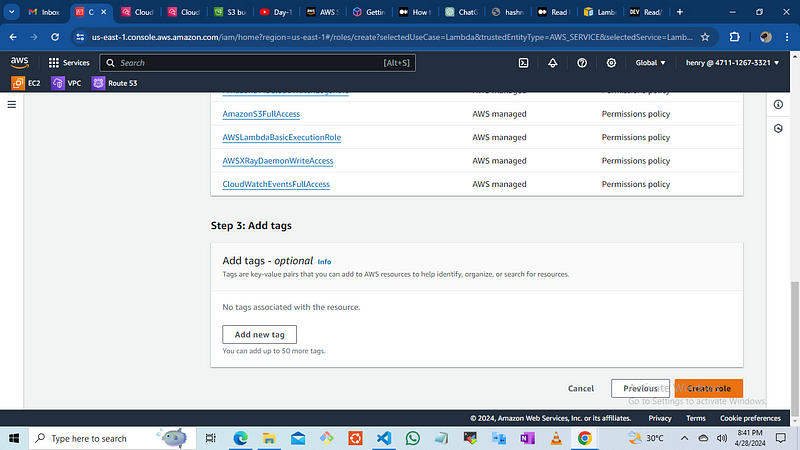
Once you have create the role
STEP 2
create the bucket, this bucket is used to trigger your lambda function and read any csv data file sent to your bucket.
Navigate to the search and type S3 then click
then click Create Bucket
add the name “pharma-data-logs”
leave all configurations as default and click on Create
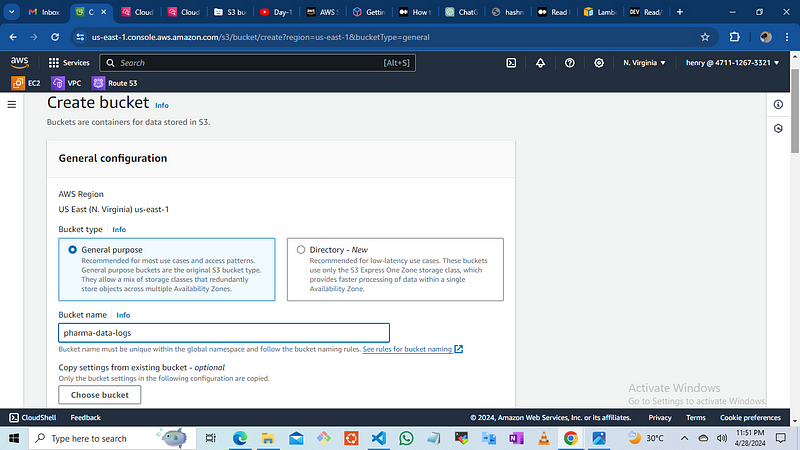
once the bucket has been created
STEP 3
we create the lambda function, using the lambda console
Navigate to the lambda console and open the functions page
click on “Author from scratch”
name the functions — “s3-datalogs-read-lambda’’
click on runtime and choose the runtime to use, select python and choose version 3.9 as the runtime “this is latest version 3.9 as at the timing of writing”.
the architecture is x86_64
then Change the default execution role and choose an execution role you created. click “use an existing role” and choose the role ‘s3-lambda-role’
then click on create
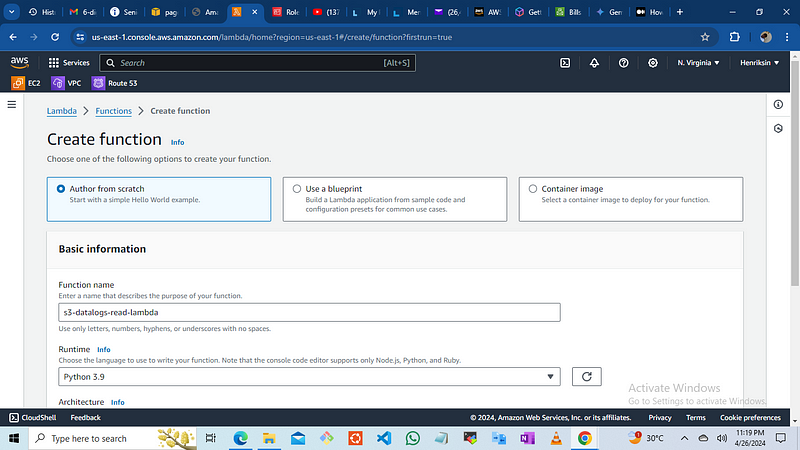
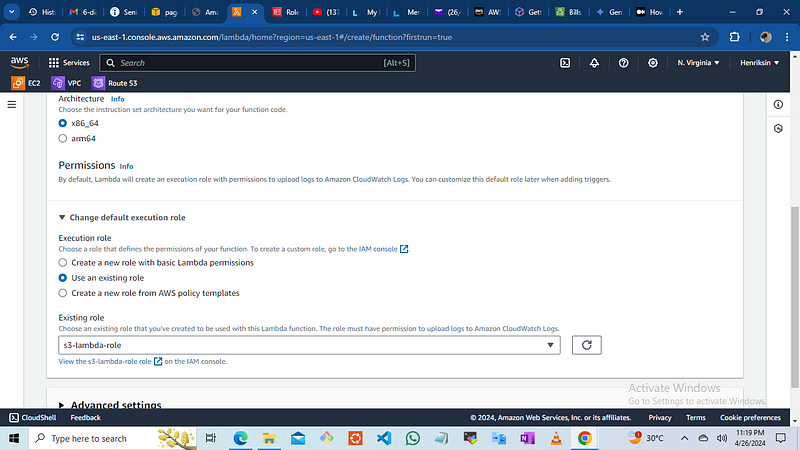
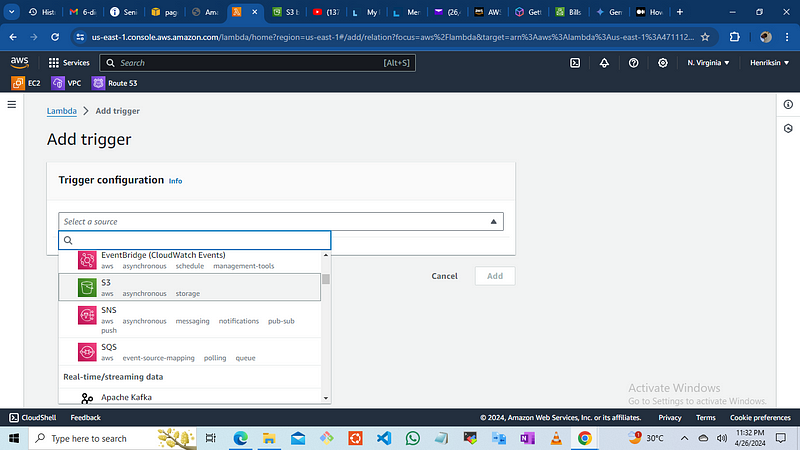
Once the function is created, we need to set up a trigger using Amazon S3. To create a trigger:
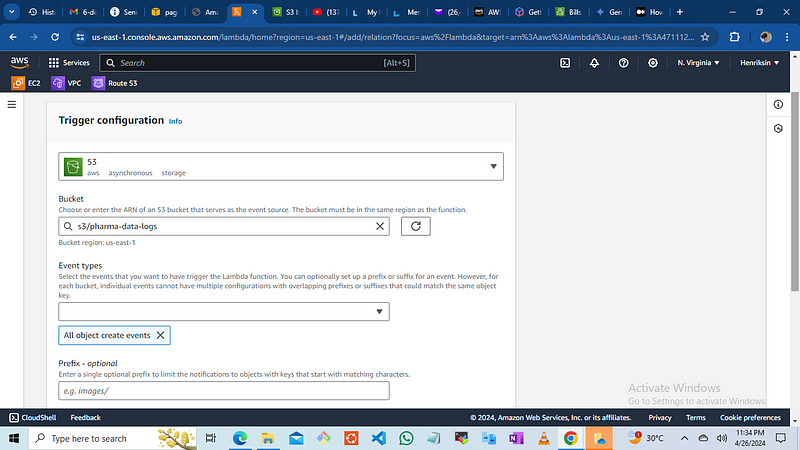
Navigate to the configuration console, select ‘Source’, and choose ‘S3’ as the trigger source.
Select the bucket name ‘Pharma-data-logs’.
For event types, choose ‘All object create events’. This setting allows the Lambda function to be triggered by any actions such as PUT, POST, or DELETE, whenever a file is uploaded to the bucket.
For the suffix, use the default setting, which can help determine specific criteria for triggering the function.”
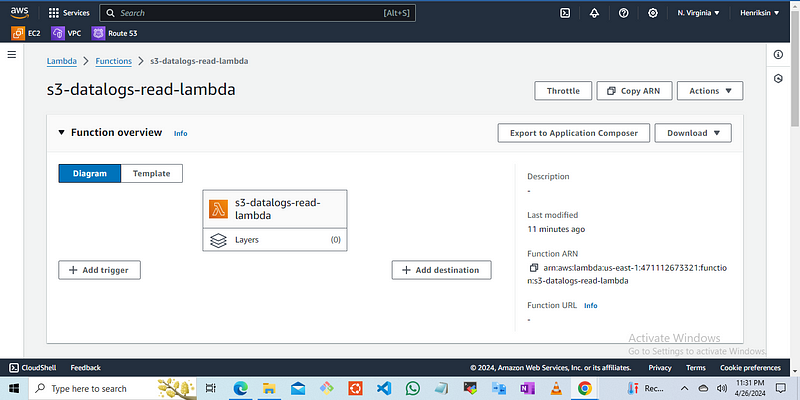
Now we create the code to run the function, replace the default code with the code of choice.
import json
import boto3
import csv
import io
s3Client = boto3.client('s3') #this is used to call the object in the bucket
def lambda_handler(event, context):
# here it will check the event records the first one 0 then it checks the s3 and find the bucket and the name using the event name
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
print(bucket)
print(key)
#determine the object
response = s3Client.get_object(Bucket=bucket, Key=key)
#Process it
data = response['Body'].read().decode('utf-8')
reader = csv.reader(io.StringIO(data))
next(reader)
for row in reader:
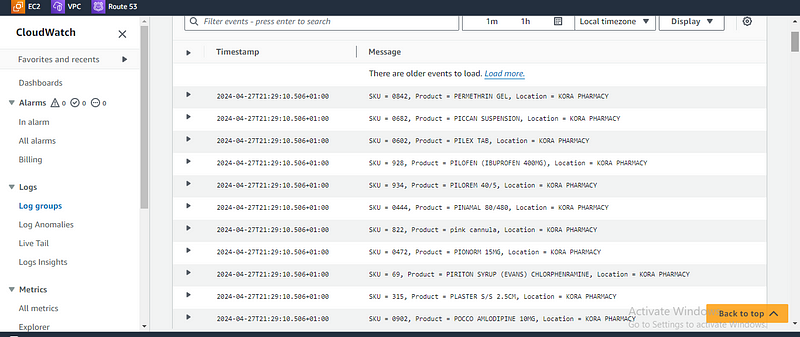
print(str.format("SKU = {}, Product = {}, Location = {}", row[0], row[1], row[2]))
Since we aren’t importing pandas modules we wont be adding layers, the layers can be used to add SDKpandas — pythons
now we click on deploy to save it.

Now we can upload the CSV file into the s3 bucket which will trigger the lambda function and it will display the data in your cloud watch logs
move to S3 console and upload the file which contains list of pharmaceutical products
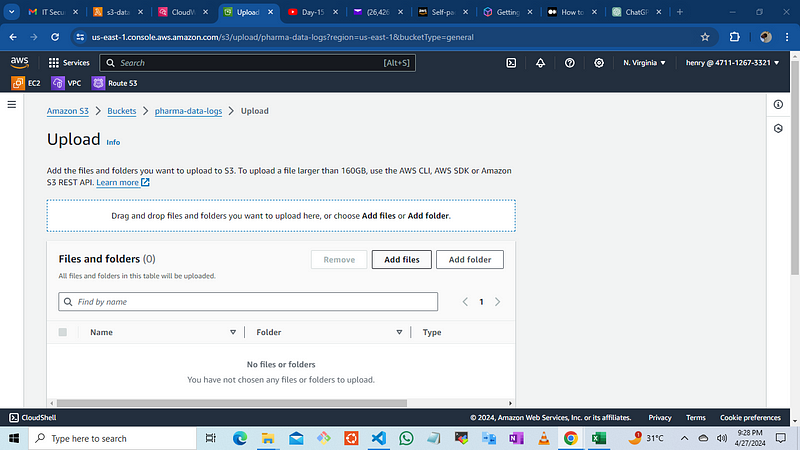
then click on add files and upload

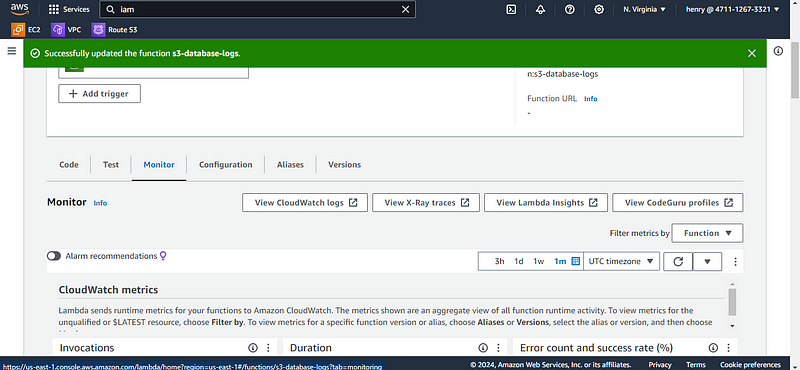
once the files are uploaded it will trigger the lambda function which will be executed and once you navigate to your lambda console click on monitor and click on view Cloud watch logs then you can now check the logs files on the logs window.
IN SUMMARY
AWS Lambda is a serverless compute service that allows you to execute code via a lambda function without the need to provision or manage servers. Using Python as our runtime, Lambda runs the code on a high-availability compute infrastructure and manages all the administrative tasks associated with the compute resources, including server and operating system maintenance, automatic scaling, and logging.
Here, we have used Amazon S3 to trigger real-time data processing in Lambda via event-based processing. This is beneficial for automating business tasks in the pharmaceutical industry that do not require a constantly running server or a scheduled job to manage the infrastructure.



